

شبکههای عصبی بازگشتی (RNN) ازجمله ابزارهای قدرتمندی هستند که برای پردازش دادههای ترتیبی و زمانی طراحی شده است و در زمینههای مختلفی ازجمله پردازش زبان طبیعی، تشخیص گفتار و پیشبینی سریهای زمانی به کار میروند. استفاده از PyTorch بهعنوان یک کتابخانه پیشرفته و کاربرپسند برای پیادهسازی و آموزشRNNها این کار را برای توسعهدهندگان و محققان حوزه هوش مصنوعی بسیار سادهتر و کارآمدتر کرده است. با ما همراه باشید تا در این سفر هیجانانگیز یاد بگیریم چگونه میتوان از شبکه عصبی بازگشتی با PyTorch برای پردازش و تحلیل دادههای ترتیبی بهره برد.
ساختار شبکههای عصبی بازگشتی
شبکههای عصبی بازگشتی (RNN) نوعی از شبکههای عصبی هستند که بهطور خاص برای پردازش دادههای ترتیبی طراحی شدهاند. ساختار RNN از گرههای تکرارشونده تشکیل شده است که هر یک میتوانند اطلاعات را از یک گام زمانی به گام بعدی منتقل کنند. این گرهها حافظهای دارند که به آنها اجازه میدهد تا اطلاعات مربوط به گامهای زمانی گذشته را ذخیره و از این اطلاعات برای تصمیمگیری در گامهای زمانی آینده استفاده کنند.
حافظه در شبکههای عصبی بازگشتی
در شبکههای عصبی معمولی، ورودیها و خروجیها مستقل از یکدیگر هستند و شبکه نمیتواند اطلاعات گذشته را به خاطر بسپارد، اما درRNNها، هر گره یک وضعیت پنهان (hidden state) دارد که بهروزرسانی میشود و اطلاعات قبلی را به گامهای زمانی بعدی انتقال میدهد. این وضعیت پنهان بهعنوان حافظه کوتاهمدت شبکه عمل میکند و بهRNNها امکان میدهد تا وابستگیهای زمانی را مدلسازی کنند.
روابط زمانی و وابستگیها
یکی از ویژگیهای کلیدیRNNها توانایی آنها در شناسایی و مدلسازی وابستگیهای زمانی است؛ برای مثال، در تحلیل زبان طبیعی معنی یک کلمه ممکن است به کلمات قبلی در جمله وابسته باشد. RNNها میتوانند این وابستگیها را درک کنند و اطلاعات مربوط به کلمات قبلی را برای تفسیر بهتر کلمات بعدی به کار ببرند. این ویژگی باعث میشود که RNNها در کاربردهایی که به پردازش دادههای ترتیبی نیاز دارند بسیار مؤثر باشند.
برای آشنایی بیشتر با این شبکهها مطلب شبکه عصبی بازگشتی (RNN) چیست و چه کاربردهایی دارد؟ را مطالعه کنید.
مشکلات شبکههای عصبی بازگشتی سنتی
با وجود مزایای زیادی که RNNها ارائه میکنند، با مشکلاتی نیز روبهرو هستند. یکی از مشکلات اصلی RNNها مشکل ناپایداری گرادیان است که در هنگام آموزش شبکههای عمیق رخ میدهد. در این حالت گرادیانها میتوانند بسیار کوچک یا بسیار بزرگ شوند که باعث مشکلاتی در بهروزرسانی وزنها و درنتیجه، کاهش دقت مدل میشود.
برای مطالعه درمورد مشکل محوشدگی گرادیان به مطلب محوشدگی گرادیان (Vanishing Gradient) چگونه رخ میدهد؟ مراجعه کنید.
بهبودهای ساختاری شبکه عصبی بازگشتی با PyTorch
برای حل مشکلات RNNهای سنتی، ساختارهای پیشرفتهتری مانند شبکههای عصبی بازگشتی طولانی کوتاهمدت (LSTM) و واحدهای بازگشتی دروازهدار (GRU) معرفی شدهاند. این ساختارها با افزودن مکانیزمهای کنترلی، مانند دروازهها، این امکان را به RNNها میدهند که اطلاعات مهم را بهمدت طولانیتری نگه دارند و مشکلات مربوط به ناپایداری گرادیان را کاهش دهند.
شبکههای عصبی بازگشتی طولانی کوتاهمدت
شبکههای عصبی بازگشتی طولانی کوتاهمدت (Long Short Term Memory) یکی از انواع پیشرفته RNNها هستند که برای بهبود عملکرد در یادگیری وابستگیهای طولانیمدت معرفی شدهاند. ساختار LSTM شامل سلولهای حافظهای است که میتوانند اطلاعات را برای مدت طولانیتری حفظ کنند. این سلولها شامل سه دروازه اصلی هستند:
- دروازه ورودی (Input Gate): این دروازه تعیین میکند که چه مقدار از اطلاعات جدید وارد سلول حافظه شود.
- دروازه فراموشی (Forget Gate): این دروازه تصمیم میگیرد که چه مقدار از اطلاعات قدیمی را فراموش کند و از حافظه پاک کند.
- دروازه خروجی (Output Gate): این دروازه تعیین میکند که چه مقدار از اطلاعات موجود در سلول حافظه به خروجی منتقل شود.
این دروازهها با کنترل جریان اطلاعات در سلولهای حافظه به LSTMها این امکان را میدهند تا اطلاعات مهم را برای مدت طولانیتری نگه دارند و مشکلات مربوط به ناپایداری گرادیان را کاهش دهند؛ درنتیجه، LSTMها میتوانند وابستگیهای طولانیمدت را بهخوبی یاد بگیرند و در کاربردهایی مانند ترجمه ماشینی و تشخیص گفتار بسیار موثر باشند.
برای آشنایی با نحوه دقیق کار LSTMها به مطلب شبکه عصبی LSTM چیست و چگونه کار میکند؟ مراجعه کنید.
واحدهای بازگشتی دروازهدار
واحدهای بازگشتی دروازهدار (Gated Recurrent Units) نوع دیگری از ساختارهای پیشرفته RNNها هستند که برای حل مشکلات RNNهای سنتی معرفی شدهاند. GRUها ساختاری سادهتر در مقایسههای LSTMها دارند و شامل دو دروازه اصلی هستند:
- دروازه بهروزرسانی (Update Gate): این دروازه تعیین میکند که چه مقدار از اطلاعات جدید به وضعیت فعلی اضافه شود و چه مقدار از وضعیت قبلی حفظ شود.
- دروازه بازنشانی (Reset Gate): این دروازه تصمیم میگیرد که چه مقدار از اطلاعات قبلی را فراموش کند و وضعیت فعلی را با اطلاعات جدید جایگزین کند.
ساختار سادهتر GRUها در مقایسه LSTMها باعث میشود که آموزش آنها سریعتر و محاسبات آنها کمهزینهتر باشد؛ بااینحال GRUها نیز میتوانند وابستگیهای طولانیمدت را بهخوبی یاد بگیرند و مشکلات مربوط به ناپایداری گرادیان را کاهش دهند. GRUها در کاربردهایی که نیاز به مدلسازی وابستگیهای زمانی دارند، مانند پیشبینی سریهای زمانی و پردازش زبان طبیعی، بسیار مؤثر هستند.
برای آشنایی با نحوه عملکرد GRUها میتوانید مطلب با شبکه عصبی واحد بازگشتی گیتی (Gated Recurrent Unit) آشنا شوید! را بخوانید.
درنتیجه، شبکههای عصبی بازگشتی با ساختارهای بهبودیافته همچنان بهعنوان یکی از ابزارهای قدرتمند در پردازش دادههای ترتیبی و مدلسازی وابستگیهای زمانی مورداستفاده قرار میگیرند و با استفاده از PyTorch میتوان بهسادگی این مدلها را پیادهسازی و آموزش داد.
مقایسه LSTM و GRU
هر دو مدل LSTM و GRU برای حل مشکلات RNNهای سنتی معرفی شدهاند و توانایی بالایی در یادگیری وابستگیهای طولانیمدت دارند؛ بااینحال تفاوتهایی نیز دارند؛ بههمین دلیل، در این جدول به مقایسه ویژگیهای کلیدی این دو نوع شبکه عصبی بازگشتی پرداختهایم که میتواند به شما ذز تصمیمگیری برای انتخاب مناسبترین مدل برای پروژههایتان کمک کند:
| ویژگی | GRU | LSTM |
| ساختار دروازهها | دارای ۲ دروازه: بهروزرسانی و بازنشانی | دارای ۳ دروازه: ورودی، فراموشی، خروجی |
| پیچیدگی | سادهتر و کمهزینهتر از نظر محاسباتی | پیچیدهتر با تواناییهای بیشتر در نگهداری حافظه |
| زمان آموزش | سریعتر بهدلیل ساختار سادهتر | کندتر بهدلیل پیچیدگی بیشتر |
| عملکرد | مناسب برای وابستگیهای زمانی کوتاهتر | مناسب برای وابستگیهای زمانی طولانیتر |
| کاربردهای مناسب | پیشبینی سریهای زمانی، پردازش زبان طبیعی با سرعت بالا | ترجمه ماشینی، تشخیص گفتار، پردازش زبان طبیعی با نیاز به دقت بیشتر |
| نیاز به حافظه | کمتر بهدلیل ساختار سادهتر | بیشتر بهدلیل داشتن سه دروازه |
| مشکلات ناپایداری گرادیان | کاهش مشکلات ناپایداری گرادیان در مقابل RNNهای سنتی | کاهش مشکلات ناپایداری گرادیان در مقابل RNNهای سنتی |
کاربردهای شبکه عصبی بازگشتی
RNNها در بسیاری از حوزهها کاربرد دارند که برخی از آنها را در ادامه بررسی میکنیم.
پردازش زبان طبیعی
یکی از کاربردهای مهم RNNها در پردازش زبان طبیعی (NLP) است. RNNها میتوانند برای ترجمه ماشینی، تحلیل احساسات، تولید متن، و تشخیص موجودیتها در متن استفاده شوند؛ بهدلیل توانایی RNNها در مدلسازی وابستگیهای زمانی، این شبکهها در پردازش زبان طبیعی بسیار مؤثر هستند.
برای آشنایی با مرحلههای انجامدادن پردازش زبان طبیعی میتوانید مطلب پردازش زبان طبیعی با پایتون چگونه انجام میشود؟ را مطالعه کنید.
پردازش صوت
RNNها، بهدلیل توانایی خود در پردازش دادههای ترتیبی، در تشخیص گفتار و تولید صدا نیز کاربرد دارند. این شبکهها میتوانند الگوهای زمانی در دادههای صوتی را شناسایی و آنها را برای تشخیص یا تولید صدا استفاده کنند.
برای مطالعه درباره پردازش صوت، مقاله پردازش صوت چیست؟ را مطالعه نمایید.
پیشبینی سریهای زمانی
RNNها میتوانند برای پیشبینی سریهای زمانی مانند پیشبینی قیمت سهام، دادههای آبوهوایی و دادههای فروش استفاده شوند. این شبکهها با مدلسازی وابستگیهای زمانی در دادهها میتوانند پیشبینیهای دقیقی ارائه کنند.
پیشنهاد میکنیم با داده های سری زمانی یا Time Series Data هم آشنا شوید.
تحلیل احساس با استفاده از شبکه عصبی بازگشتی با PyTorch
در این قسمت، هدف ما پیادهسازی یک مدل تحلیل احساسات با استفاده از شبکههای عصبی بازگشتی (RNN) و بردارهای تعبیه کلمات (Word Embeddings) مدل BERT است. این روش ترکیبی از قدرت RNNها در مدلسازی وابستگیهای زمانی و توانایی مدل BERT در استخراج ویژگیهای غنی از متون است. تحلیل احساسات به شناسایی و استخراج احساسات بیانشده در متنها میپردازد و در کاربردهای مختلفی از جمله تحلیل نظرات کاربران، پایش رسانههای اجتماعی و خدمات مشتریان استفاده میشود.
فراخوانی کتابخانههای موردنیاز
ابتدا کتابخانههای لازم برای پردازش زبان طبیعی، یادگیری عمیق و سایر کارها را فراخوانی میکنیم:
import nltknltk.download('stopwords')from nltk.corpus import stopwordsnltk.download("wordnet")nltk.download('omw-1.4')from nltk.corpus import wordnet as wnnltk.download('punkt')from nltk.tokenize import word_tokenizeimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.optim.lr_scheduler import StepLRfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoader, Datasetfrom transformers import BertTokenizer, BertModelimport osimport reimport requestsimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.manifold import TSNEfrom sklearn.model_selection import train_test_split
دانلود و آمادهسازی دادههای IMDB
در این بخش، دادههای مربوط به نظرات IMDB را دانلود میکنیم. دادهها شامل دو مجموعه از نظرات مثبت و منفی هستند که از دو URL جداگانه دانلود میشوند. سپس این دادهها را به فهرستهایی از نظرات (Reviews) و برچسبهای (Labels) مربوط تبدیل میکنیم. برچسب ۱ نشاندهنده نظرات مثبت و برچسب ۰ نشاندهنده نظرات منفی است. هدف از این مرحله تهیه دادههای خام برای مرحلههای بعدی پیشپردازش و مدلسازی است:
def download_imdb_data(): pos_url="https://raw.githubusercontent.com/dennybritz/cnn-text-classification-tf/master/data/rt-polaritydata/rt-polarity.pos" neg_url="https://raw.githubusercontent.com/dennybritz/cnn-text-classification-tf/master/data/rt-polaritydata/rt-polarity.neg" pos_reviews = requests.get(pos_url).text.split('\n') neg_reviews = requests.get(neg_url).text.split('\n') reviews = pos_reviews + neg_reviews labels = [1] * len(pos_reviews) + [0] * len(neg_reviews) return reviews, labelsreviews, labels = download_imdb_data()
پیشپردازش متون
در این مرحله، متون ورودی را پیشپردازش و پاکسازی میکنیم. این کار باعث میشود از دادههای تمیز و یکنواختی برای آموزش مدل تهیه شود. این عملیات شامل مراحل زیر است:
- تبدیل به حروف کوچک: با این کار تمامی کاراکترها را به حروف کوچک تبدیل میکنیم تا یکپارچگی دادهها حفظ شود.
- حذف علائم نگارشی و کاراکترهای غیرحرفی: با استفاده از کتابخانه regular expressions، تمامی کاراکترهای غیرحرفی (مانند اعداد و علامتها) را حذف میکنیم.
- tokenize کردن متن: با این کار جملهها را به توکنهای مجزا تقسیم میکنیم.
- حذف کلمات توقف: کلمههای توقف مانند (the ،is و in ) را که اهمیت معنایی کمتری دارند حذف میکنیم.
- حذف کلمات کوتاه: در این قسمت کلماتی که طول آنها کمتر از دو حرف است را حذف میکنیم.
- تبدیل به رشته: در پایان توکنهای باقیمانده را مجدداً به یک رشته حروف (همان جمله) تبدیل میکنیم.
stop_words = stopwords.words('english')def clean_text(sentence): sentence = str(sentence).lower() sentence = re.sub('[^a-z]',' ',sentence) sentence = word_tokenize(sentence) sentence = [i for i in sentence if i not in stop_words] sentence = [i for i in sentence if len(i)>2] sentence=" ".join(sentence) return sentence
چگونه ابر کلمات بسازیم؟
بیایید قبل از ساخت یک مدل شبکه عصبی بازگشتی با PyTorch ابر کلمات (Word Cloud) متن نظرات کاربران را با قطعه کد زیر بسازیم:
from wordcloud import WordCloudpositive_text=" ".join([review for review, label in zip(reviews, labels) if label == 1])negative_text=" ".join([review for review, label in zip(reviews, labels) if label == 0])positive_wordcloud = WordCloud(width=800, height=400, background_color="white").generate(positive_text)negative_wordcloud = WordCloud(width=800, height=400, background_color="white").generate(negative_text)plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.imshow(positive_wordcloud, interpolation='bilinear')plt.title('Positive Reviews Word Cloud')plt.axis('off')plt.subplot(1, 2, 2)plt.imshow(negative_wordcloud, interpolation='bilinear')plt.title('Negative Reviews Word Cloud')plt.axis('off')plt.show()
خروجی کد بالا بهشکل زیر است:
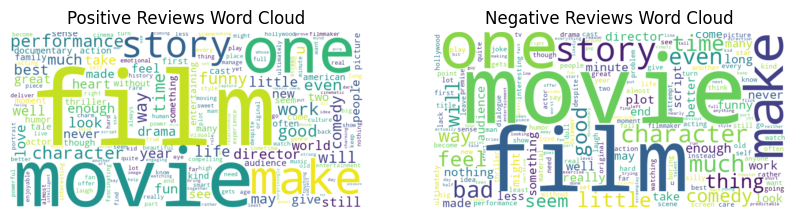
در تصویر دو ابر کلمه مشاهده میشود که کلمات پرتکرار در نظرات مثبت و منفی کاربران را نشان میدهند. در نظرات مثبت (ابر کلمه سمت چپ)، کلماتی مانند «فیلم»، «داستان»، «یک»، «ساخت»، «اجرا» و «بهترین» بیشتر تکرار شدهاند که نشاندهنده تأکید بر جنبههای مثبت فیلم است. در نظرات منفی (ابر کلمه سمت راست)، کلماتی مانند «فیلم»، «یک»، «ساخت»، «احساس»، «داستان» و «بد» بیشترین تکرار را دارند که بر نکات منفی فیلم تمرکز دارد. تکرار کلمات مشترکی مثل «فیلم»، «یک» و «ساخت» نشاندهنده حضور مکرر این کلمات در هر دو کلاس مثبت و منفی است و تاثیری در القای حس کاربر ندارد.
تقسیم دادهها به مجموعههای آموزشی و آزمایشی
در این بخش دادهها را به دو مجموعه آموزشی و آزمایشی تقسیم میکنیم تا بتوانیم مدل را آموزش داده و سپس عملکرد آن را ارزیابی کنیم. این تقسیمبندی را با استفاده از تابع train_test_split از کتابخانه scikit-learn انجام میدهیم که دادهها را به نسبت ۸۰ به ۲۰ به دو مجموعه تقسیم میکند. همچنین، تابع clean_text که در بخش قبل آن را ساختیم، برای تمیز کردن متون بر روی هر دو مجموعه اعمال میکنیم:
X_train, X_val, y_train, y_val = train_test_split(reviews, labels, test_size=0.2, random_state=42)for txt in X_train: txt = clean_text(txt)for txt in X_val: txt = clean_text(txt)
استفاده از مدل BERT برای tokenize کردن
در مرحله بعد، از tokenizer و مدل پیشآموزشدیده BERT برای تبدیل متنها به بردارهای تعبیه کلمات استفاده میشود. مدل BERT به دلیل آموزش دیدن روی حجم زیادی از دادههای متنی، توانایی بالایی در استخراج ویژگیهای معنایی و نحوی از متنها دارد. توکنایزر BERT متنها را به توکنهای ورودی تبدیل میکند که برای ورودی به مدل استفاده میشوند.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')embedder = BertModel.from_pretrained('bert-base-uncased')embedder.eval()
تعریف کلاس دیتاست
برای مدیریت دادههای آموزشی و آزمایشی، یک کلاس پایتورچی Dataset تعریف میکنیم. این کلاس ۳ متد اصلی دارد:
- __init__: این متد دادهها را دریافت و در متغیرهای داخلی ذخیره میکند.
- __getitem__: این متد یک نمونه داده را بر اساس ایندکسی که دارد بازمیگرداند.
- __len__: این متد طول دیتاست را بازمیگرداند.
این کلاس را برای سادهسازی فرآیند آماده کردن دادهها برای ورودی به DataLoader استفاده میکنیم:
class MyDataset(Dataset): def __init__(self, encoded, label): self.input_ids = encoded['input_ids'] self.attention_mask = encoded['attention_mask'] self.label = label def __getitem__(self, index): ids = self.input_ids[index] masks = self.attention_mask[index] lbls = self.label[index] return ids, masks, lbls def __len__(self): return len(self.input_ids)
ساخت دیتاستهای آموزشی و آزمایشی
در این قسمت، دادههای آموزشی و آزمایشی را با استفاده از توکنایزر BERT توکنایز کرده و سپس آنها به دیتاستهای سفارشی تبدیل میکنیم. درادامه این دیتاستها به DataLoader داده میشوند تا در طول فرایند آموزش بهصورت دستهای (Batch) به مدل داده شوند:
train_encoded = tokenizer(X_train, padding=True, truncation=True, max_length=100, return_tensors="pt")trainset = MyDataset(train_encoded, y_train)train_loader = DataLoader(trainset, batch_size=16)val_encoded = tokenizer(X_val, padding=True, truncation=True, max_length=100, return_tensors="pt")valset = MyDataset(val_encoded, y_val)val_loader = DataLoader(valset, batch_size=16)
تعریف مدل LSTM
مدل شبکه عصبی ما که از کلاس nn.Module ارثبری میکند، شامل لایههای BERT ،LSTM ،Dropout و یک لایه کاملاً متصل (Fully Connected) است:
class SentimentClassifier(nn.Module): def __init__(self, embedder, hidden_dim, output_dim, drop_prob=0.3): super(SentimentClassifier, self).__init__() self.bert = embedder self.lstm = nn.LSTM(embedder.config.hidden_size, hidden_dim, num_layers=1, batch_first=True) self.dropout = nn.Dropout(drop_prob) self.fc = nn.Linear(hidden_dim, output_dim) self.sigmoid = nn.Sigmoid()
در این معماری:
- embedder مدل پیشآموزشدیده BERT است که برای استخراج بردارهای تعبیه کلمههای متن ورودی استفاده میشود.
- hidden_dim تعداد نورونها در لایه مخفی LSTM را مشخص میکند. این عدد را خودمان مقداردهی میکنیم و نشان میدهد که چقدر اطلاعات میخواهیم در هر زمان در واحد LSTM نگهداری کنیم.
- num_layers تعداد لایههای LSTM است که ما آن را برابر یک قرار دادیم.
- output_dim تعداد واحدهای خروجی در لایه کاملا متصل است که در این مثال برابر با ۱ تنظیم میشود؛ زیرا ما یک مدل دستهبندی باینری داریم.
- drop_prob احتمال خاموششدن نورونهاست که به صورت پیشفرض برابر ۰.۳ است.
این مدل بهاین صورت عمل میکند که ابتدا لایه BERT توکنهای ورودی را به بردارهای تعبیه کلمات تبدیل میکند. سپس لایه LSTM این بردارهای تعبیهشده را میگیرد و وابستگیهای زمانی بین آنها را مدلسازی میکند. بعد از آن، لایه Dropout برای کاهش Overfitting و بهبود تعمیمپذیری مدل به کار میرود. در ادامه، لایه کاملاً متصل (Linear) خروجی لایه LSTM با اندازه hidden_dim را دریافت و آنها را به خروجی نهایی با اندازه output_dim تبدیل میکند. در پایان، خروجی لایه کاملاً متصل به تابع فعالساز سیگموئید داده میشود که خروجی را به یک مقدار میان ۰ و ۱ میرساند و نشاندهنده احتمال تعلق متن به کلاس مثبت است.
تابع forward
سپس در همین کلاس، متد forward را نیز میسازیم. این متد نحوه عبور دادههای ورودی از لایههای شبکه عصبی بازگشتی با PyTorch را بهصورت گامبهگام تعریف و خروجی نهایی را تولید میکند:
def forward(self, input_ids, attention_mask): bert_outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask) bert_embeddings = bert_outputs.last_hidden_state lstm, (h_n, c_n) = self.lstm(bert_embeddings) drop = self.dropout(lstm[:, -1, :]) out = self.fc(drop) return self.sigmoid(out)
با کمک این تابع، last_hidden_state را از bert_outputs استخراج کرده و به متغیر bert_embeddings اختصاص میدهیم. last_hidden_state شامل تعبیههای نهایی برای هر توکن ورودی است. این بردارهای تعبیه کلمات به لایه LSTM داده میشوند که خروجی آن شامل دو بخش است. یکی از این بخشها (lstm) خروجی لایه LSTM در یک گام زمانی (time step) است. در پایان، با lstm[:, -1, :] آخرین خروجی LSTM را برای هر نمونه در batch انتخاب میکنیم.
حال مدل را تعریف کرده و در متغیر model میریزیم:
model = SentimentClassifier(embedder, hidden_dim=16, output_dim=1)
آمادهسازی برای آموزش
در این مرحله ابتدا مدل را به دستگاه GPU منتقل میکنیم:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')model = model.to(device)
سپس تابع هزینه Binary Cross Entropy و بهینهساز Adam را تعریف میکنیم. پارامتر weight_decay را بهمنظور (L2) Regularization و بهعنوان جریمهای برای وزنهای بزرگ اضافه میکنیم. همچنین از تنظیمکننده نرخ یادگیری StepLR استفاده میکنیم که به صورت خودکار نرخ یادگیری را در طول فرایند آموزش تغییر میدهد تا به بهبود عملکرد مدل کمک کند. متغیر step_size در این تابع تعداد دورههای (epochs) بین هر کاهش نرخ یادگیری و متغیر gamma ضریبی است که تعیین میکند نرخ یادگیری جدید چند برابر نرخ یادگیری فعلی باشد. در اینجا، نرخ یادگیری پس از هر ۵ دوره به یک صدم مقدار قبلی کاهش مییابد:
criterion = nn.BCELoss().to(device)optimizer = optim.Adam(model.parameters(), lr=1e-5, weight_decay=1e-8)scheduler = StepLR(optimizer, step_size=5, gamma=0.01)
آموزش مدل
در این بخش ابتدا چند پارامتر برای کنترل فرایند آموزش مدل تنظیم میکنیم. با num_epochs تعداد کل دورههای آموزش را مشخص میکنیم و در متغیر patience تعداد دورههایی را تعیین میکنیم که قبل از توقف زودهنگام (Early stopping) مدل باید حتی بدون بهبود در خطای ارزیابی به آموزش ادامه دهد. best_val_loss برای ذخیره کمترین مقدار خطای ارزیابی در طول آموزش استفاده میشود و best_epoch دورهای را که بهترین مدل در آن ذخیره شده، نگهداری میکند. همچنین، model_dir مسیری را برای ذخیره مدلهای بهینه تعیین میکند:
num_epochs = 20patience = 3 best_val_loss = float('inf')best_epoch = 0model_dir = "model_checkpoints" os.makedirs(model_dir, exist_ok=True)
سپس، مدل را برای چندین دوره (epoch) آموزش میدهیم. برای این منظور ابتدا مدل را در حالت آموزش قرار میدهیم. سپس دادههای آموزشی را به مدل میدهیم و خروجی مدل را با برچسبهای واقعی مقایسه میکنیم تا خطا محاسبه شود. سپس، وزنهای مدل را با استفاده از الگوریتم بهینهسازی بهروزرسانی میکنیم:
train_losses = []val_losses = []for epoch in range(num_epochs): model.train() epoch_train_loss = 0 for train_input_ids, train_attention_mask, train_labels in train_loader: train_input_ids = train_input_ids.to(device) train_attention_mask = train_attention_mask.to(device) train_labels = train_labels.to(device) optimizer.zero_grad() outputs = torch.flatten(model(train_input_ids, train_attention_mask)) loss = criterion(outputs, train_labels.float()) loss.backward() optimizer.step() epoch_train_loss += loss.item() scheduler.step() epoch_train_loss /= len(train_loader) train_losses.append(epoch_train_loss)
ارزیابی مدل
در این مرحله مدل را در حالت ارزیابی قرار داده، دادههای ارزیابی را به مدل میدهیم، خطای ارزیابی را محاسبه و سپس ذخیره میکنیم. دقت کنید که این کد باید در ادامه کد قبلی و داخل حلقه for اول اجرا شود:
model.eval() epoch_val_loss = 0 with torch.no_grad(): for val_input_ids, val_attention_mask, val_labels in val_loader: val_input_ids = val_input_ids.to(device) val_attention_mask = val_attention_mask.to(device) val_labels = val_labels.to(device) val_outputs = torch.flatten(model(val_input_ids, val_attention_mask)) loss = criterion(val_outputs, val_labels.float()) epoch_val_loss += loss.item() epoch_val_loss /= len(val_loader) val_losses.append(epoch_val_loss) print(f'Epoch [{epoch + 1}/{num_epochs}], Training Loss: {epoch_train_loss:.4f}, Validation Loss: {epoch_val_loss:.4f}')
درادامه برای پیادهسازی مکانیزم توقف زودهنگام (Early Stopping) بررسی میکنیم که آیا خطای ارزیابی در دوره (epoch) جاری بهبود یافته است یا خیر. اگر خطای اعتبارسنجی کاهش یافته باشد، best_val_loss به مقدار جدید بهروزرسانی و best_epoch به دوره فعلی تنظیم میکنیم؛ سپس مدل را با استفاده از torch.save ذخیره میکنیم. اگر تفاوت بین دوره فعلی و best_epoch بیشتر از مقدار patience باشد، فرایند آموزش متوقف میشود. این کار را بهمنظور جلوگیری از Overfitting انجام میدهیم. این قسمت هم باید در هر epoch اجرا شود پس باید در ادامه حلقه for اول قرار بگیرد:
if epoch_val_loss < best_val_loss: best_val_loss = epoch_val_loss best_epoch = epoch torch.save(model.state_dict(), os.path.join(model_dir, 'best_model.pth')) print(f'Best model saved at epoch {epoch + 1}') if epoch - best_epoch > patience: print(f'Early stopping at epoch {epoch + 1}') break
بارگذاری بهترین مدل و فاز پیشبینی
پس از اتمام آموزش، بهترین مدل شبکه عصبی بازگشتی با PyTorch ذخیره شده را بارگذاری میکنیم:
model.load_state_dict(torch.load(os.path.join(model_dir, 'best_model.pth')))print('Best model loaded.')
سپس برای پیشبینی روی دادههای آزمایشی از بهترین مدل استفاده میکنیم:
model.eval()all_predictions = []all_labels = []with torch.no_grad(): for test_input_ids, test_attention_mask, test_labels in val_loader: test_input_ids = test_input_ids.to(device) test_attention_mask = test_attention_mask.to(device) test_labels = test_labels.to(device) outputs = model(test_input_ids, test_attention_mask) predicted_classes = (outputs > 0.5).float() all_predictions.extend(predicted_classes.cpu().numpy()) all_labels.extend(test_labels.cpu().numpy())correct_predictions = (np.array(all_predictions).flatten() == np.array(all_labels)).sum()accuracy = correct_predictions / len(all_labels)print(f'Accuracy: {accuracy:.4f}')
بهاینترتیب مدل ما نهایتاً با دقت ۸۵ درصد توانست مثبت یا منفی بودن احساس کاربران را تشخیص دهد.
مجموعه کامل کدهای بالا را میتوانید در این ریپازیتوری از گیتهاب مشاهده نمایید.
پیشبینی ارزش سهام به کمک شبکه عصبی بازگشتی با PyTorch
همانطور که گفتیم، یکی از کارهایی که RNNها قادر به انجامدادن آن هستند پیشبینی سریهای زمانی است. در این قسمت نیز ما قصد داریم قیمتهای آینده سهام شرکت اپل (AAPL) را با استفاده از دادههای تاریخی پیشبینی کنیم. هدف اصلی آموزش یک مدل پیشبینیکننده است که بتواند قیمتهای آینده سهام را پیشبینی کند. درواقع مدل با تحلیل الگوها و روندهای موجود در دادههای تاریخی، سعی میکند قیمتها لحظه بستهشدن سهام را برای روزهای آینده پیشبینی کند. مرحلههای انجامدادن این پروژه بهاین شرح است:
نصب کتابخانه yfinance
با نصب این کتابخانه میتوانیم دادههای تاریخی سهام را بهراحتی از Yahoo Finance دریافت کنیم که برای تحلیل و پیشبینی قیمتها ضروری است:
!pip install yfinance
فراخوانی کتابخانههای موردنیاز
در این بخش، کتابخانههای موردنیاز را وارد میکنیم:
import torchimport numpy as npimport pandas as pdimport yfinance as yfimport torch.nn as nnimport torch.optim as optimimport matplotlib.pyplot as pltfrom sklearn.preprocessing import MinMaxScaler
دانلود و پیشپردازش دادهها
در این بخش، دادههای تاریخی قیمت سهام شرکت اپل (AAPL) را از Yahoo Finance دانلود میکنیم:
df = yf.download('AAPL', start="2010-01-01", end='2021-01-01')
سپس قیمتهای بستهشدن را استخراج و دادهها را با استفاده از MinMaxScaler نرمالسازی میکنیم تا در محدوده ۱- و ۱+ قرار گیرند:
data = df['Close'].values.astype(float)scaler = MinMaxScaler(feature_range=(-1, 1))data_normalized = scaler.fit_transform(data.reshape(-1, 1))
درادامه تابع create_sequences برای ایجاد توالیهای داده تعریف میکنیم:
def create_sequences(data, seq_length): # Initialize a list to store input sequences xs = [] # Initialize a list to store target values ys = [] for i in range(len(data)-seq_length): # Extract a sequence of length seq_length x = data[i:i+seq_length] # Extract the next data point y = data[i+seq_length] # Append the sequence to the input list xs.append(x) # Append the target value to the target list ys.append(y) return np.array(xs), np.array(ys)
برای ایجاد مجموعهداده مناسب، هر توالی از ۳۰ قیمت متوالی تشکیل و مقدار بعدی بهعنوان هدف استفاده میشود:
seq_length = 30X, y = create_sequences(data_normalized, seq_length)
سپس دادهها را بهنسبت ۸۰ / ۲۰ به مجموعههای آموزشی و آزمایشی تقسیم میکنیم:
train_size = int(len(X) * 0.8)X_train, X_test = X[:train_size], X[train_size:]y_train, y_test = y[:train_size], y[train_size:]
تعریف مدل GRU
در این بخش برای ساخت یک مدل GRU (واحد بازگشتی دروازهدار) را با استفاده از nn.Module در پایتورچ تعریف میکنیم. کلاس GRUModel شامل دو تابع اصلی است: __init__ که پارامترهای مدل را مقداردهی اولیه میکند و forward که مراحل اجرای مدل را تعریف میکند. این مدل شامل یک لایه GRU و یک لایه کاملاً متصل (nn.Linear) است که خروجی لایه GRU را به مقدار هدف تبدیل میکند. این معماری مدل برای گرفتن وابستگیهای زمانی در دادههای سری زمانی بسیار مناسب است:
class GRUModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size, num_layers=2, dropout_prob=0.2): super(GRUModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.num_layers = num_layers self.gru = nn.GRU(input_size, hidden_layer_size, num_layers, dropout=dropout_prob) self.linear = nn.Linear(hidden_layer_size, output_size) self.hidden_cell = torch.zeros(self.num_layers, 1, self.hidden_layer_size)
که در آن پارامترهای زیر مشاهده میشود:
input_size
input_size اندازه ورودی است و تعداد ویژگیهایی را که در هر گام زمانی به مدل GRU داده میشود تعیین میکند؛ برای مثال، اگر دادههای ما فقط شامل قیمت بستهشدن سهام باشد، input_size برابر با ۱ خواهد بود.
hidden_layer_size اندازه لایه پنهان است که تعداد نورونها یا واحدهای عصبی در هر لایه مخفی GRU را تعیین میکند. این اندازه تأثیر مستقیم بر ظرفیت یادگیری مدل و دقت پیشبینیهای آن دارد.
output_size
output_size اندازه خروجی مدل است و تعداد نورونهای لایه خروجی را تعیین میکند. در مسائل پیشبینی سری زمانی، معمولاً output_size برابر با ۱ است زیرا ما به دنبال پیشبینی یک مقدار آینده هستیم (مثلاً قیمت بستهشدن روز بعد در مثال ما).
num_layers
num_layers تعداد لایههای GRU را در مدل تعیین میکند. هر لایه اضافی به مدل اجازه میدهد تا ویژگیهای پیچیدهتر و وابستگیهای بلندمدتتری را یاد بگیرد.
dropout_prob
dropout_prob احتمال دراپاوت را تعیین میکند که یک تکنیک برای جلوگیری از بیشبرازش است. دراپاوت بهطور تصادفی نورونها را در طول آموزش غیرفعال میکند تا مدل به طور کلیتر یاد بگیرد. برای مثال در مدل ما، اگر مقداری برای این پارامتر تعیین نشود، به طور پیشفرض ۲۰ درصد نورونها در هر لایه را غیرفعال میکند.
hidden_cell در GRU به عنوان یک حافظه برای نگهداری اطلاعات مهم از ورودیهای قبلی عمل میکند. این وضعیت پنهان به مدل کمک میکند تا وابستگیهای زمانی را در دادهها یاد بگیرد. این متغیر ابتدا توسط یک تنسور به ابعاد تعداد تعداد لایههای GRU در ۱ در اندازه لایه پنهان که تماما با صفر مقداردهی شده، ایجاد میشود. سپس در متد forward، به عنوان ورودی به لایه GRU داده میشود و در طول پردازش بهروزرسانی میشود. عدد یک بهعنوان بعد دوم این تنسور، اندازه batch (تعداد نمونهها در هر دسته) را مشخص میکند. در اینجا فرض شده که هر بار یک نمونه پردازش میشود.
در ادامه در همین کلاس GRUModel، متد forward را تعریف میکنیم:
def forward(self, input_seq): reshaped_input = input_seq.view(len(input_seq), 1, -1) gru_out, self.hidden_cell = self.gru(reshaped_input, self.hidden_cell) predictions = self.linear(gru_out.view(len(input_seq), -1)) return predictions[-1]
که در آن reshaped_input ورودی تغییر شکل داده شده به فرمت مناسب برای یک واحد GRU است، self.hidden_cell اول وضعیت پنهان قبلی است که به GRU داده میشود، gru_out خروجی GRU در تمام گامهای زمانی و self.hidden_cell دوم وضعیت پنهان بهروزرسانی شده برای گامهای زمانی بعدی است.
مقداردهی اولیه مدل، تابع هزینه و بهینهساز
در این بخش، مدل GRU را با استفاده از پارامترهای مشخص مقداردهی اولیه میکنیم. اندازه ورودی به ۱ تنظیم میشود زیرا تنها از یک ویژگی (قیمت بستهشدن) استفاده میکنیم. اندازه لایه پنهان به ۱۰۰ و تعداد لایههای GRU به ۲ تنظیم میکنیم. مدل با استفاده از این پارامترها ایجاد میشود:
model = GRUModel(input_size=1, hidden_layer_size=100, output_size=1, num_layers=2, dropout_prob=0.2)
سپس تابع MSELoss را که میانگین مربع خطا میان مقدارهای پیشبینیشده و واقعی را اندازهگیری میکند، بهعنوان تابع هزینه مدل تعریف میکنیم:
loss_function = nn.MSELoss()
حال بهینهساز Adam را با نرخ یادگیری ۰.۰۰۱ برای بهروزرسانی پارامترهای مدل استفاده میکنیم:
optimizer = optim.Adam(model.parameters(), lr=0.001)
آموزش مدل
در این بخش، فرایند آموزش مدل شبکه عصبی بازگشتی با PyTorch را اجرا میکنیم. مدل برای تعداد دورههای مشخص (num_epochs) آموزش داده میشود. در هر دوره، مدل را به حالت آموزش (model.train) تنظیم کرده و دادههای آموزشی را در دستههای (batches) مختلف بارگذاری میکنیم. برای هر دسته، گرادیانهای بهینهساز صفر میشوند و hidden_cell بازنشانی (Reset) میشود تا از وضعیت پنهان قبلی پاک شود و مدل بتواند با وضعیت اولیه شروع به کار کند. سپس مدل پیشبینی خود را انجام میدهد، تابع هزینه محاسبه و گرادیانها به عقب انتشار (Backpropagate) مییابند. سپس بهینهساز پارامترهای مدل را بهروزرسانی میکند:
epochs = 200for epoch in range(epochs): model.train() for seq, labels in zip(X_train, y_train): optimizer.zero_grad() model.hidden_cell = torch.zeros(model.num_layers, 1, model.hidden_layer_size) pred_train = model(seq) train_loss = loss_function(pred_train, labels) train_loss.backward() optimizer.step()
ارزیابی مدل
پس از هر دوره، مدل را به حالت ارزیابی (model.eval) تنظیم میکنیم تا پارامترهای آن در طول تست تغییر نکند. مانند قسمت آموزشی، hidden_cell را مجددا با مقدار صفر بازنشانی میکنیم. با torch.no_grad از محاسبه گرادیان جلوگیری میکنیم تا فرآیند ارزیابی سریعتر و کارآمدتر انجام شود. در این بخش نیز دادههای تست را در دستههای (batches) مختلف بارگذاری میکنیم برای هر دسته، مدل بهروش گفتهشده پیشبینی خود را انجام میدهد و مقدار تابع هزینه محاسبه میشود:
model.eval() with torch.no_grad(): for seq, labels in zip(X_test, y_test): model.hidden_cell = torch.zeros(model.num_layers, 1, model.hidden_layer_size) pred_test = model(seq) test_loss = loss_function(pred_test, labels)
پیشبینی با مدل
در این بخش برای مشاهده عملکرد نهایی مدل، ابتدا مدل را به حالت ارزیابی (evaluation mode) منتقل میکنیم تا پارامترهای مدل در حین پیشبینی ثابت بمانند و گرادیانها محاسبه نشوند. سپس یک فهرست برای ذخیره پیشبینیهای دادههای آموزشی ایجاد میکنیم. برای هر دنباله (sequence) در دادههای آموزشی، با استفاده از torch.no_grad مطمئن میشویم که گرادیانها محاسبه نشوند و حالت پنهان (hidden cell state) را با صفر بازنشانی میکنیم؛ سپس دنباله دادهها را به مدل داده و پیشبینی مدل را ذخیره میکنیم.
model.eval()train_predictions = []for seq in X_train: with torch.no_grad(): model.hidden_cell = torch.zeros(model.num_layers, 1, model.hidden_layer_size) train_predictions.append(model(seq).item())
همین روند برای دادههای آزمایشی نیز تکرار میشود:
test_predictions = []for seq in X_test: with torch.no_grad(): model.hidden_cell = torch.zeros(model.num_layers, 1, model.hidden_layer_size) test_predictions.append(model(seq).item())
در ادامه لازم است مقدارهای پیشبینیشده و واقعی از مقیاس نرمالسازیشده را به مقیاس اصلی بازگردانیم. این فرآیند امکان مقایسه دقیقتر بین پیشبینیها و مقادیر واقعی را فراهم میکند و ارزیابی مدل را در مقیاس واقعی دادهها ممکن میکند:
# Inverse transform the scaled train/test predictions back to the original scaletrain_predictions = scaler.inverse_transform(np.array(train_predictions).reshape(-1, 1))test_predictions = scaler.inverse_transform(np.array(test_predictions).reshape(-1, 1))# Convert y_train/y_test from a PyTorch tensor to a NumPy array and reshape it for the inverse transformy_train = scaler.inverse_transform(y_train.numpy().reshape(-1, 1))y_test = scaler.inverse_transform(y_test.numpy().reshape(-1, 1))
در پایان برای ترسیم نمودار دادههای واقعی و پیشبینیهای مدل، ابتدا دادههای واقعی آموزشی و آزمایشی را با استفاده از شاخصهای دادههای اصلی (df.index) ترسیم میکنیم. سپس پیشبینیهای مدل برای هر دو مجموعه داده را با استفاده از همان شاخصها ترسیم میکنیم. این نمودار به مقایسه عملکرد مدل با دادههای واقعی کمک میکند و نمایش بصری از دقت پیشبینیهای مدل را فراهم میکند:
# Plot the actual training dataplt.plot(df.index[:len(y_train)], y_train, label="Train Data")# Plot the actual test dataplt.plot(df.index[len(y_train):len(y_train)+len(y_test)], y_test, label="Test Data")# Plot the model's predictions for the training dataplt.plot(df.index[:len(train_predictions)], train_predictions, label="Train Predictions")# Plot the model's predictions for the test dataplt.plot(df.index[len(train_predictions):len(train_predictions)+len(test_predictions)], test_predictions, label="Test Predictions")
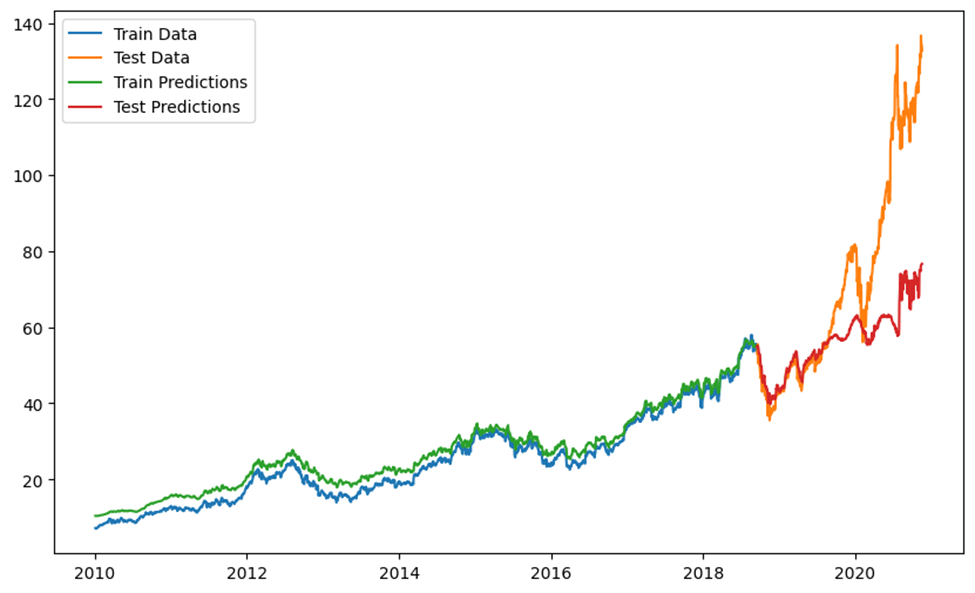
این نمودار به مقایسه دادههای واقعی و پیشبینیهای مدل برای مجموعههای آموزشی و آزمایشی میپردازد. محور افقی نمایانگر زمان از سال ۲۰۱۰ تا ۲۰۲۰ است و محور عمودی مقادیر دادهها را نشان میدهد. دادههای واقعی آموزشی با رنگ آبی و دادههای واقعی آزمایشی با رنگ نارنجی نمایش داده شدهاند. پیشبینیهای مدل برای دادههای آموزشی با رنگ سبز و پیشبینیهای مدل برای دادههای آزمایشی با رنگ قرمز ترسیم شدهاند. این نمودار نشان میدهد که شبکه عصبی بازگشتی با PyTorch در پیشبینی دادههای آموزشی و آزمایشی نسبتا خوب عمل کرده و توانسته است روند کلی دادهها پیشبینی کند.
مجموعه کامل کدهای بالا را میتوانید در این ریپازیتوری از گیتهاب مشاهده نمایید.
کلام آخر درباره شبکه عصبی بازگشتی با PyTorch
شبکههای عصبی بازگشتی (RNN) ابزارهای قدرتمندی برای پردازش دادههای ترتیبی و زمانی هستند که در زمینههای مختلفی از جمله پردازش زبان طبیعی، تشخیص گفتار و پیشبینی سریهای زمانی کاربرد دارند. با این حال، چالشهایی مانند ناپایداری گرادیان در هنگام آموزش این شبکهها وجود دارد که میتواند دقت و کارایی آنها را تحت تاثیر قرار دهد. برای حل این مشکلات، ساختارهای پیشرفتهتری مانند شبکههای عصبی بازگشتی طولانی-کوتاهمدت (LSTM) و واحدهای بازگشتی دروازهدار (GRU) معرفی شدهاند. این ساختارها با مکانیزمهای کنترلی مانند دروازهها، اطلاعات مهم را برای مدت طولانیتری نگه داشته و مشکلات مربوط به ناپایداری گرادیان را کاهش میدهند.
پیادهسازی و آموزش شبکه عصبی بازگشتی با PyTorch کار را برای توسعهدهندگان و محققان حوزه هوش مصنوعی بسیار سادهتر و کارآمدتر کرده است. PyTorch امکان استفاده از مدلهای پیشآموزشدیده مانند BERT برای ترکیب قدرت RNNها در مدلسازی وابستگیهای زمانی و توانایی استخراج ویژگیهای غنی از متون را فراهم میکند. این قابلیتها به خصوص در کاربردهایی مانند تحلیل احساسات و پیشبینی سریهای زمانی مفید هستند.
به طور کلی، شبکههای عصبی بازگشتی با استفاده از بهبودهای ساختاری جدید و بهرهگیری از ابزارهایی مانند PyTorch، میتوانند نتایج بسیار موثری در تحلیل و پردازش دادههای ترتیبی ارائه دهند و به عنوان یکی از ابزارهای اصلی در هوش مصنوعی مورد استفاده قرار گیرند.

پرسشهای متداول
شبکههای عصبی بازگشتی (RNN) چه تفاوتی با شبکههای عصبی معمولی دارند؟
شبکههای عصبی بازگشتی برای پردازش دادههای ترتیبی طراحی شدهاند و میتوانند اطلاعات زمانی را از یک گام زمانی به گام بعدی منتقل کنند& درحالی که شبکههای عصبی معمولی ورودیها و خروجیها را مستقل از یکدیگر پردازش میکنند و قادر به حفظ حافظه زمانی نیستند.
چرا مشکل ناپایداری گرادیان در RNNها رخ میدهد و چگونه میتوان آن را رفع کرد؟
ناپایداری گرادیان زمانی رخ میدهد که در هنگام آموزش شبکه، گرادیانها بسیار کوچک یا بسیار بزرگ شوند. این مسئله باعث مشکلاتی در بهروزرسانی وزنها و کاهش دقت مدل میشود. استفاده از ساختارهای پیشرفته مانند LSTM و GRU که دارای مکانیزمهای کنترلی مثل دروازهها (Gates) هستند، میتواند این مشکل را کاهش دهد.
تفاوتهای کلیدی بین LSTM و GRU چیست و هر یک در چه شرایطی بهتر عمل میکنند؟
LSTM و GRU هر دو برای یادگیری وابستگیهای طولانیمدت طراحی شدهاند. LSTM دارای سه دروازه (ورودی، فراموشی، خروجی) است و ساختار پیچیدهتری دارد، درحالیکه GRU دو دروازه (بهروزرسانی، بازنشانی) دارد و سادهتر است. LSTM در مسائلی که نیاز به حافظه طولانیتر دارند، بهتر عمل میکند و GRU در مواردی که سرعت آموزش و کارایی محاسباتی مهم است برتری دارد.
چگونه میتوان از شبکه عصبی بازگشتی با PyTorch برای تحلیل احساسات استفاده کرد؟
برای تحلیل احساسات به کمک RNNها، یکی از روشها این است که از بردارهای تعبیه کلمات (Word Embeddings) مانند BERT بهعنوان ورودی استفاده کرد. این روش ترکیبی از قدرت RNNها در مدلسازی وابستگیهای زمانی و توانایی مدل BERT در استخراج ویژگیهای غنی از متون است. پس از پیشپردازش متون و تبدیل آنها به بردارهای تعبیهشده، میتوان مدل RNN را آموزش داد تا احساسات مثبت یا منفی را تشخیص دهد.
چه کاربردهایی برای RNNها در پیشبینی سریهای زمانی (Time Series Forecasting) وجود دارد؟
RNNها میتوانند برای پیشبینی سریهای زمانی مانند پیشبینی قیمت سهام، دادههای آب و هوایی و دادههای فروش استفاده شوند. این شبکهها با مدلسازی وابستگیهای زمانی در دادهها میتوانند پیشبینیهای دقیقی ارائه کند؛ برای مثال، مدلهای GRU و LSTM میتوانند الگوهای زمانی موجود در دادههای تاریخی را شناسایی و برای پیشبینی مقادیر آینده استفاده کنند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران آقای وب به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
دوره جامع دیتا ساینس و ماشین لرنینگ












